Abstract
Building general-purpose models that can perceive diverse real-world modalities and solve various tasks is an appealing target in artificial intelligence.
In this paper, we present ChatBridge, a novel multimodal language model that leverages the expressive capabilities of language as the catalyst to bridge the gap between various modalities. We show that only language-paired two-modality data is sufficient to connect all modalities. ChatBridge leverages recent large language models (LLM) and extends their zero-shot capabilities to incorporate diverse multimodal inputs.
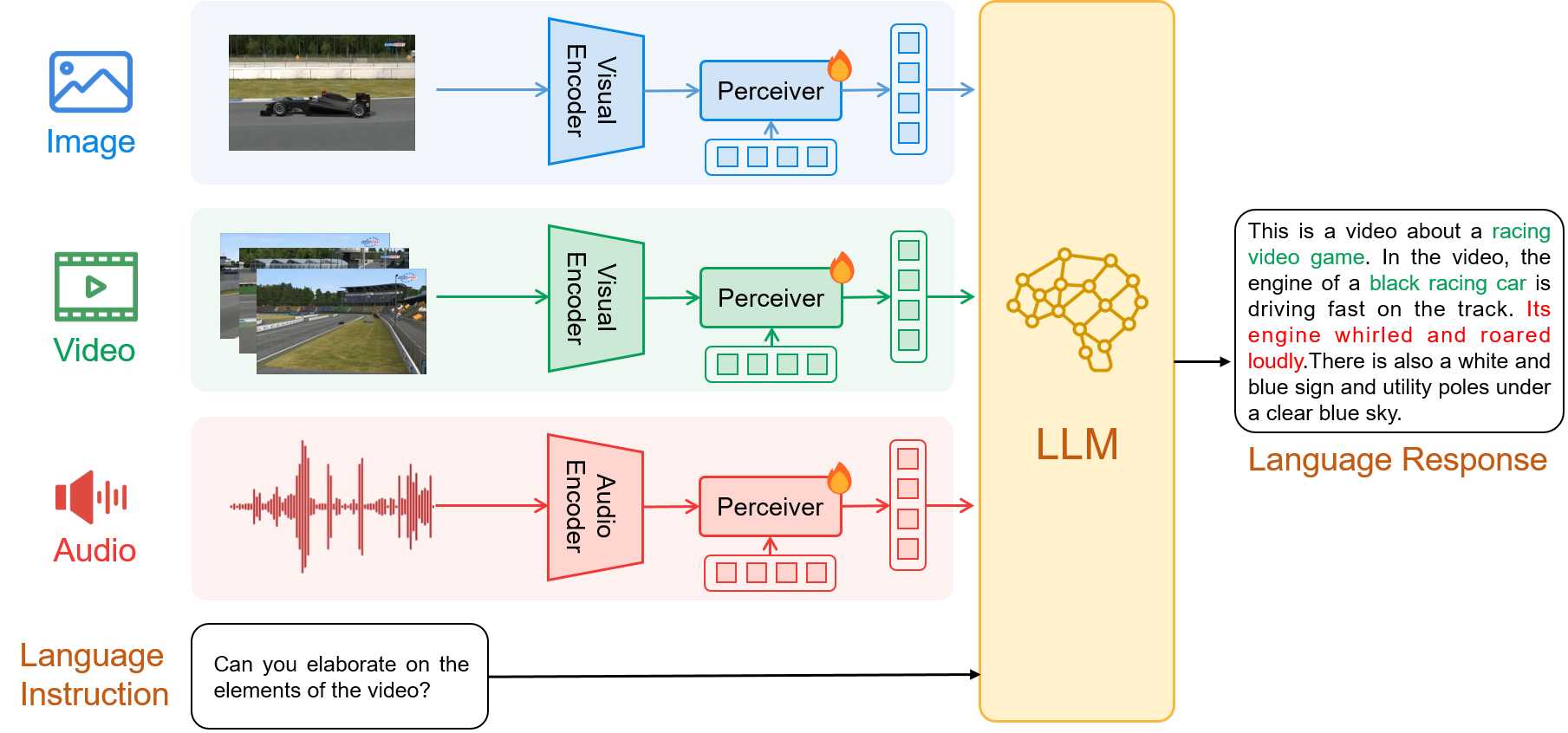
ChatBridge undergoes a two-stage training. The first stage aligns each modality with language, which brings emergent multimodal correlation and collaboration abilities. The second stage instruction-finetunes ChatBridge to align it with user intent with our newly proposed multimodal instruction tuning dataset, named MULTIS, which covers a wide range of 16 multimodal tasks of text, image, video, and audio modalities.
We show strong quantitative and qualitative results on zero-shot multimodal tasks covering text, image, video, and audio modalities. All codes, data, and models of ChatBridge will be open-sourced.
 MULTimodal InStruction
Datasets (MULTIS)
MULTimodal InStruction
Datasets (MULTIS)
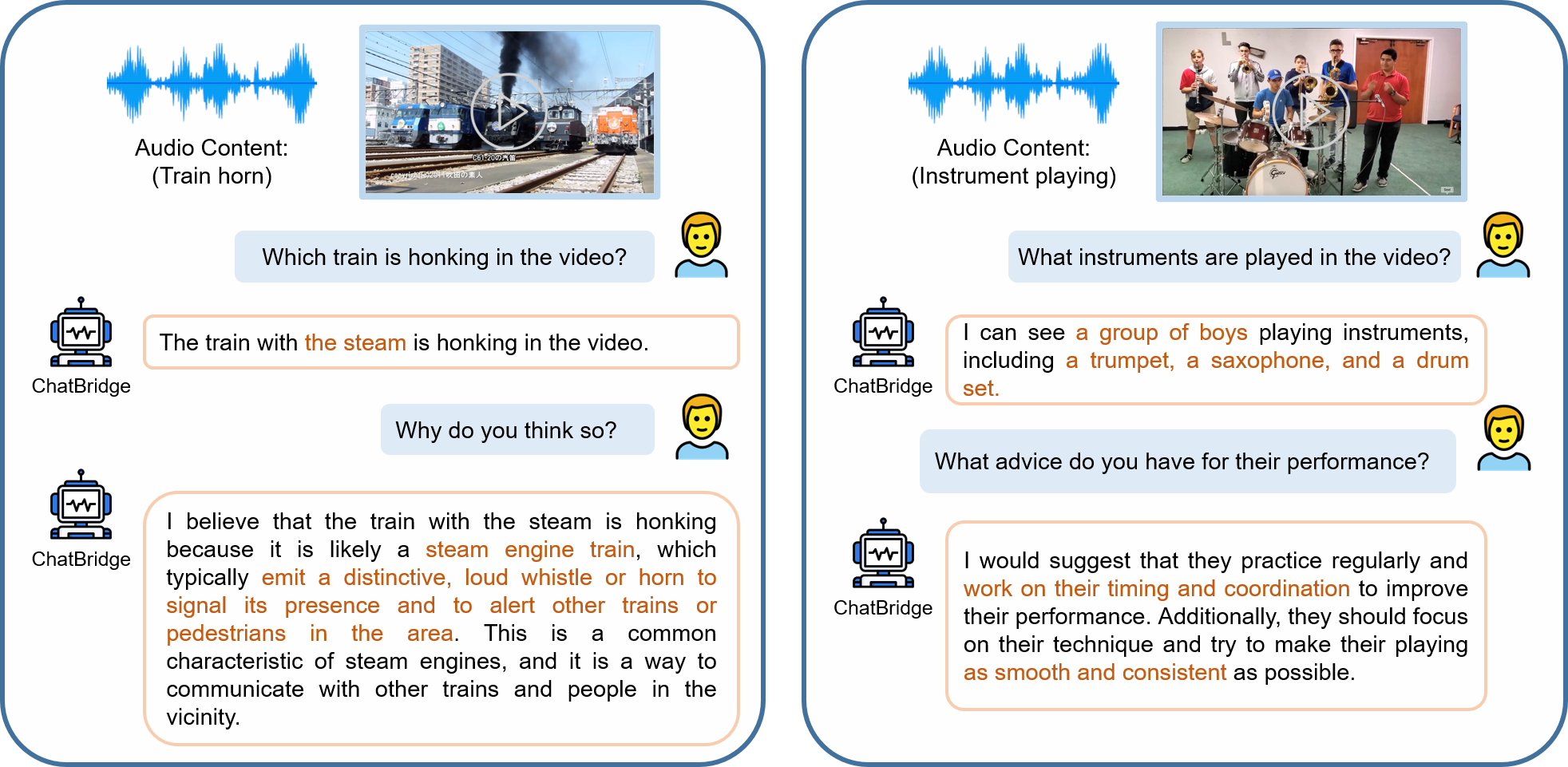
 Examples of multimodal
chat
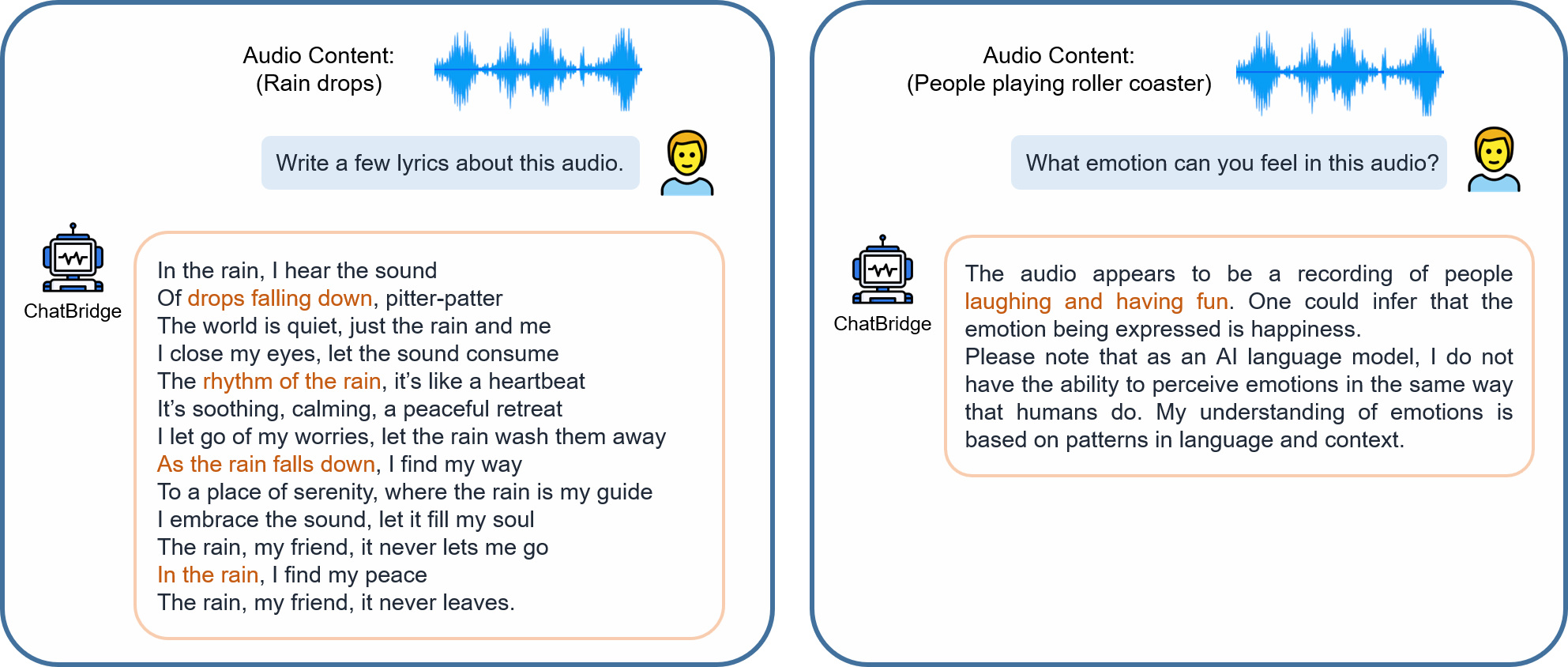
Examples of multimodal
chat